
Aus gutem Grund empfehle ich allen die mich auf Computer-Themen ansprechen die Installation von Linux. Wer allerdings noch nie damit gearbeitet hat, der/die muß relativ viel neues lernen. Das zahlt sich allerdings auch aus. Dieser Kurs ist für EinsteigerInnen gedacht die einen Überblick über Linux bekommen wollen. Neben rein technischen Themen gibt es dabei auch einen politischen Überblick über die Vorteile des Systems.
Bei der Auswahl der etwas näher Behandelten Programme habe ich auch darauf geachtet, was für uns politische AktivistInnen am ehesten relevant ist.
Angesichts Totalüberwachung und der Kontrolle der Geheimdienste durch Rechtsextremisten gibt es natürlich einen Schwerpunkt zum Thema Sicherheit und Verschlüsselung.
Ein Linux-System ist heute relativ einfach und schnell zu installieren und kann sehr weit rein auf der grafischen Oberfläche benutzt werden. Den echten Komfort eines Linux Systems merkt man/frau aber erst auf der Kommandozeile. In den weiter hinten liegenden Kapital geht das dann durchaus auch etwas in die Tiefe. Damit man/frau sich zu Helfen weiß, falls das System mal nicht so funktioniert wie es soll.
Die Aktuelle Version dieses Documents findest du auf https://mond.at/lk
Linux ist ein freies Betriebssystem. Ein Betriebssystem kümmert sich um den Zugriff auf die Hardware. Es verwaltet den Speicher, es “weiß” wie man Daten auf eine Festplatte schreibt, wie die Netzwerk-Karte angesprochen werden will, etc, etc.
Zum Betriebssystem gehört der so genannten “Kernel”, der die oben erwähnten Aufgaben war nimmt und zusätzlich auch noch mehr oder weniger viele System und Anwenderprogramme die das ganze darum herum regeln. Z.b. Wie das verarbeiten eingegebener Befehle.
Das Betriebssystem bietet also Schnittstellen für andere Programme die dort laufen können (eine so genannte API) und eine Schnittstelle für die BenutzerInnen (z.b. Befehlseingabe und optional eine graphische Oberfläche).
Die Schnittstellen von Linux entsprechen denen von Unix. Vom GNU Projekt wurden viele Freie Unix Programme geschaffen auf denen die dann Linux aufbauen konnte. GNU ist eine rekursive Abkürzung für “GNU is Not Unix”.
“Freie Software” und “Open Source” werden oft synonym benutzt. Richard Stallman, Vordenker der Bewegung bevorzugt den Begriff “Freie Software” um auf den politischen Aspekt hinzuweisen. “Open Source” wird i.a. von der libertären Seite benutzt: Die den Vorteil von Software, die mit Source Code, den man/frau auch selbst Verändern kann, zwar schätzen aber dies nicht als politisches Statement sehen wollen.
Als politisch aktive Menschen sollten wir daher eher den Begriff “Freie Software” verwenden, auch wenn der Begriff “Open Source” weiter verbreitet ist. Als Kompromiss bietet sich FLOSS an: “Free Libre Open Source Software”.
Die Frage ist oft auch eine praktische: Wann ist Software “frei”?
Z.b: Manche Firmen geben ihre Software mit Source Code weiter, erlauben aber dessen Verwendung nur sehr eingeschränkt.
Eine praktische Definition zur Unterscheidung der sehr vielen Software Lizenzen wurde mit den “Debian Free Software Guidelines (DFSG)” geschaffen.
Für Richard M. Stallman (RMS) ist das “frei” wie in “Freiheit” und nicht wie in “Freibier” gemeint. Es geht um unsere Rechte.
Eine der wichtigsten Software Lizenzen ist die von Stallman geschaffene GPL.
Gibt es auch Nachteile? Ja: Manchmal ist freie Software nicht so “glattpoliert” wie manche kommerzielle Produkte. Für manche Aufgaben gibt es auch fast nur kommerzielle Software.
Die GPL “General Public Licence” (Oft auch GNU Licence genannt, da von Stallman für die GNU Projekt entworfen) garantiert 4 Freiheiten:
Vorteil der GPL ist, dass der Code der von der Community geschaffen wurde nicht von kommerziellen Konzernen missbraucht werden kann: Diese dürfen die Software zwar auch, wie alle Anderen, verwenden, müssen aber, wenn sie diese in Produkte einbauen, den Source Code auch unter GPL wieder weiter geben. Oft ist es für Firmen Sinnvoll das zu tun und damit vergrößert sich der Pool freier Software. (Die GPL ist “viral”).
Die wichtigste anderen freie Lizenz ist die BSD (bzw. BSD artige Lizenzen. z.b. MIT). Sie erlaubt mehr oder weniger “alles”. Allerdings auch: die Weiterverwendung des Source Codes in kommerziellen Produkten bei denen der Code nicht weiter gegeben wird.
Firmen können BSD Lizensierte Freie Software daher leicht “stehlen”. Microsoft und Apple haben sehr viel BSD lizensierten Code verwendet.
Die von Lawrence Lessig entwickelten CC (“Creative Commons”) Linzenzen haben die GNU und die BSD Lizenzen als Vorbild. Die Vielfalt der Optionen bei CC bringt aber auch Probleme mit sich.
Der Erfolg freier Software in unserer Welt ist ein Beleg dafür, dass diese mit dem Kapitalismus bis zu einem gewissen Grad kompatibel ist. Firmen haben ein Interesse daran. Auch Firmen wie Google oder Apple wollen nicht von Microsoft abhängig sein. Firmen schätzen alles was Kosten senkt und wenn Freie Software das kann dann wird es auch eingesetzt.
Andererseits ist verwirklicht freie Software doch vieles von dem was wir als Kommunismus verstehen. Das Eigentum an Software wird, unter Ausnützung des Copyrights, aufgehoben und die Freiheit der Software wird damit geschützt. In Freie Software sehen wir die freie Kooperation freier Individuen - soweit diese unter den gegebenen Umständen möglich ist.
Man spricht daher auch von einer “Keimform”. Freie Software zielt in Richtung “Überwindung des Kapitalismus”, kann aber mit in ihm wachsen.
Ich denke das sollte für uns politische AktivistInnen durchaus Beispielcharakter haben: Wir müssen unsere Aktivitäten so gestalten, dass sie im hier und jetzt wachsen können und gleichzeitig auf die Veränderung eben dieser herrschenden Verhältnisse abzielen.
Zwei weitere Prinzipien aus der Produktion Freier Software die, meiner Meinung nach, für uns Relevant sind: “Forks” und “Show Running Code”
Ist jemand mit der Richtung in die sich ein Projekt entwickelt nicht einverstanden, so kann er oder sie das Projekt jederzeit “forken”. D.h. man/frau macht Entwicklungen in eine andere Richtung. Wenn der Source Code dann auseinander läuft ist das zwar Ineffizient (und somit die Motivation hoch, einen Fork zu vermeiden und doch zusammen an einem Code-Strang zu Arbeiten hoch) aber immer eine Option. Die Freiheit getrennte Wege zu gehen besteht immer und wird ab und zu auch in Anspruch genommen.
Oft meinen Menschen sie müssten mit guten Anregungen helfen. Wer aber wirklich etwas bewegen will sollte doch mit machen. Linus Torvalds, Ursprünglicher Entwickler von Linux, antwortet mit dem berühmten “Show running Code” einem anderen Entwickler der meinte man solle bestimmte Dinge ganz anders machen.
Hier also für uns als AktivistInnen: Wer es anders will muss auch mitmachen.
Einige dieser Überlegungen sind in den Artikel
http://qummunismus.at/p/article120.html eingeflossen.
Mehr Überlegenungen zur politischen Relevanz auch auf: http://mond.at/texte/soak05_freie_software.html
Ein Linux kann heute durchaus gut ohne Kommandozeile benutzt werden. Für fast alles gibt es gute grafische Programme. Dennoch lohnt es sich auch in die Kommandozeile (“Command Line Interface (CLI)”) einzusteigen. Eine gut gestaltetest CLI hat gegenüber einer grafischen Oberfläche durchaus viele Vorteile:
Natürlich hat auch eine GUI ihre Vorteile - insbesondere dort wo auch die Problemstellungen grafischer Natur sind: z.B. ein Zeichenprogramm.
Der Kern von Linux ist der “Kernel”. Der wird z.b. auch in Android (Googles Betriebsystem für Handys) verwendet. Allerdings hat Android dort nur Google-eigene Programme laufen. Viele davon ohne Source-Code, auch wenn Teile von Android auch unter einer relativ freien Lizenz verfügbar sind.
Der Linux Kernel und zum Teil auch Linux Programme werden in vielen Appliances (z.B. WLAN-Router, Alarmanlagen, NAS-Storage Server, etc, etc) eingesetzt. Dort hat man/frau als normale/r AnwenderIn meist keinen direkten Zugang zum System sondern nutzt das Ganze über ein Webinterface.
Üblicherweise meint man mit Linux aber ein mehr oder weniger vollständiges Linux (GNU/Linux) mit allen wichtigen Systemprogrammen. Man kann diese Programme auch immer selbst “compilieren” (d.g. vom Source Code in ein Programm umwandelt). Das ist jedoch aufwendig. Daher nimmt man i.a. fertige Distributionen in denn schon alle wichtigen Programme enthalten sind.
Mac OS/X ist ein kommerzielles Unix von Apple (das aus einem freien BSD Unix heraus entwickelt wurde aber jetzt nicht mehr frei ist). Wer sich auf der Linux Kommandozeile zuhause fühlt wird sich auch auf einem Mac mehr oder weniger zurecht finden. Die grafische Oberfläche ist aber nicht direkt mit der Unix X Oberfläche kompatibel. Viele freie Software und viele Linux Programme wurden auf Mac-OS/X portiert und können dort verwendet werden.
Obwohl Apple enorm von freier Software profitiert hat (Ohne den BSD Kernel wäre ihr hoffnungslos veraltetes und instabiles Mac-OS9 wohl das Ende von Apple am Desktop gewesen) ist Apple der Idee von Freier Software eher feindlich eingestellt.
Freie Programme können natürlich relativ leicht auf andere Systeme portiert werden. Viel der nützlichen Linux Programme wurden daher auch auf Microsoft-Windows portiert. Gimp, Inkscape, Blender, etc. können alle auch dort, mehr oder weniger gut, verwendet werden.
Chrome-OS Googles Chrom-OS ist ein schlankes Betriebsystem für Desktops. Es kommt ebenfalls mit einem Linux-Kernel ist aber kein volles Linux sondern nur als Unterlage für Googles Chrome-Web-Browser gedacht.
Wer längere Zeit mit Linux arbeitet will i.a. nicht mehr zurück. Gerade für den Umstieg am Anfang ist aber eine gleichzeitige Nutzung oft hilfreich. Am Ende ist es aber immer besser zu versuchen die Dinge die früher mit kommerziellen Programmen erledigt wurden mit Freien zu versuchen.
Dabei gibt es folgende Möglichkeiten:
Dabei gibt es zwei grundsätzlich verschiedene Möglichkeiten:
Die remote Funktionen sind natürlich auch für den Zugriff auf virtualisierte Systeme nützlich.
Neben Linux gibt es auch heute immer noch kommerzielle Unixe: z.B.: Solaris (oracle) oder IBMs AIX. Üblicherweise werden auch auf kommerziellen Unixen heutzutage viele GNU Tools installiert. Man/frau fühlt sich dort auch “zuhause”.
Weiters gibt es viele freie, von BSD abstammende Unixe. z.B. FreeBSD oder OpenBSD. Im Vergleich zu Linux führen diese aber eher ein Nischendasein.
Da Linux frei ist kann jede/r kommen und es sich so einrichten und zusammenstellen wie er/sie möchte. Das ist viel Arbeit aber dennoch gibt es verschiedene Zusammenstellungen (Distributionen). Üblicherweise mit verschiedenen Schwerpunkten und Zielsetzungen.
Eines der wichtigeren Entscheidungskriterien ist, welches Packetmanagment System verwendet wird. Es gibt Debian (.deb) und RedHat (.rpm).
Manche Hersteller packen zu den freien Linux Programmen auch noch kommerzielle Programme dazu und/oder bieten kommerziellen Support an.
Hier eine unvollständige Auflistung wichtiger Distributionen
Was ist die besten Distribution für EinsteigerInnen? Ich empfehle Debian oder Ubuntu. Persönlich bevorzuge ich Debian.
Live-CDs sind CDs oder USB-Sticks, die direkt gestartet werden können, ohne dass dazu ein System installiert werden muss. Das ist praktisch fürs Ausprobieren aber auch nützlich für Troubleshooting (Wenn z.b. der Computer nicht mehr startet und man herausfinden will was das Problem ist), aber auch für Sicherheitsrelevante Operationen.
Hier 3 wichtige Live Systeme:
Wir gehen hier davon aus, dass das System fertig aufgesetzt ist und zur Benutzung bereitsteht.
Linux bietet mehrere “virtuelle” Bildschirme an, zwischen denen man/frau umschalten kann. Es gibt “grafische” Bildschirme und “Text Consolen”.
Auf der Text Console steht meist irgend etwas von “tty” und “login:”. Auf der grafischen Oberfläche gibt es ein Bild mit einer Anmeldemaske.
Umschalten kann man (wenn das nicht explizit ausgeschalten ist) mit: Ctrl-Alt-F1 bis Ctrl-Alt-F91 . D.h. Die Strg Taste gemeinsam mit der linken Alt Taste (i.a. links neben der Leertaste) und gemeinsam mit der Funktionstaste F1 drücken.2
Wichtige andere Tastenkombinationen:
Ctrl-Alt-Backspace 3 . Killed die grafische Oberfläche (die Taste ist aber oft ist deaktiviert).
Ctrl-Alt-Delete 4 Startet den Computer (sauber) neu. Ist aber meist nur in der Text-Console erlaubt.
Basis ist ein Programm das den Bildschirm verwaltet. Meist Xserver oder X11 genannt. Manche Distributionen setzen auch auf ein neueres System namens “Wayland”.
Darauf läuft zunächst ein Programm zum einloggen. Üblicherweise kann dort auch ausgewählt werden welche der verschiedenen grafischen Oberflächen man/frau benutzen will. Es können auch mehrere BenutzerInnen gleichzeitig eingeloggt sein und man/frau kann zwischen diesen wechseln.
Um eine bestimmte Oberfläche auszuwählen muss vor dem Einloggen das Settings/Zahnrad Symbol geklickt werden.
Welchen man/frau benutzen will ist Geschmackssache. Am besten einmal ausprobieren:
Ein Windowmanager ermöglicht das Umschalten zwischen Programmen, Vergrössern, Verkleinern, etc. Ein Desktop-Environment kommt zusätzlich mit Funktionen für Datei-Managment und Weitere Funktionen.
Üblicherweise ist es kein Problem, z.B.: für KDE Entwickelte Programme im GNOME zu benutzen und umgekehrt.
Alle BenutzerInnen können sich eigene Desktop Umgebungen aussuchen, bevorzugte Sprache und sogar andere Zeitzonen.
Am Beginn der Linux Benutzung steht die Wahl eines Passwortes. Extrem wichtig ist es hier ein gutes Passwort zu wählen. (Linux bietet viele Möglichkeiten der Remote-Nutzung und damit kann ein Linux Computer mit einem schlechten Passwort sehr schnell gehackt werden. Auch wenn man/frau initial keine Remote-Zugriffe einplant: besser gleich ein gutes Passwort wählen:
sudo su - macht eine/n BenutzerIn zum root. apt-get update - holt sich eine aktuellisierte liste der verfügbaren Packete einer debian basierenden Distribution. apt-get upgrade - erneuert alle Packte (meist Sicherheitsupdates). apt-get install programmname - installiert ein neues Programm mit genau diesem namen. apt-cache search nach-irgenwas - sucht nach-irgendwas in der liste der Programmpackete - falls der genaue Name des Programms nicht bekannt ist.
Wichtigstes Werkzeug für fast alles heutzutage ist der Web-Browser. Folgendes steht zur Auswahl:
z.B.: wget https://mond.at/cd/txt/0001-ssh.txt
Sehr leicht lassen sich damit auch ganze Websites spiegeln.
Alle Desktop Umgebungen kommen auch mit grafischen Datei-Managern. Egal ob man/frau den grafischen Datei-Manager benutzt oder auf ob auf der Text-Konsole gearbeitet wird, brauchen wir einen Überblick wo Dinge abgespeichert werden.
Im Unterschied zu Windows und DOS werden im Linux, so wie in anderen Unixen auch, Verzeichnisse und
Dateinamen mit einem Schrägstrich nach vorne “/” getrennt. Im Unterschied zu DOS und Windows gibt es keine
Laufwerksbuchstaben. Andere Laufwerke werden als so genannte “mounts” an beliebiger Stelle im Baum eingehängt.
Was im Windows C:
ist, ist im Linux bloß / - d.h. das so genannte “root Verzeichnis” - die Wurzel des Baumes. Wie im Windows ist
punkt-punkt .. ein Wechsel auf das darüberliegende Verzeichnis. Ein Punkt alleine: . meint immer das
aktuelle Verzeichnis. Beginnt ein Verzeichnispfad mit einem / so ist dies ein “absoluter Pfad” - d.h. vom
Root-Verzeichnis weg. Ohne diesen / am Anfang ist es ein “relativer Pfad” - d.h.: vom aktuellen Verzeichnis
ausgehend.
Ein weiterer, wichtiger Unterschied zu Windows: Linux ist “case-sensitive”. Groß- und Kleinschreibung werden unterschieden. bild.jpg und Bild.jpg sind zwei verschiedene Dateien.
Files und Verzeichnisse die mit einem Punkt beginnen, sind so genannte “hidden files” und werden normalerweise nicht angezeigt.6
Eine Tilde-Slash ˜/ ist oft ein Kürzel für das eigene Home-Verzeichnis.
Umlaute, Leerzeichen und Sonderzeichen sollten in Datei- und Verzeichnisnamen vermieden werden. Minus und Underline sind aber Ok. Es funktionieren auch alle anderen Zeichen (ausser / ) aber man kann sich damit verschiedene Probleme einfangen. (Z.b. beim Austausch mit anderen Betriebssystemen oder beim Eintippen auf der CLI).
Im eignen Home-Verzeichnis kann man/frau sich frei bewegen. Übliche Konventionen sind aber: Desktop/ entählt Dateien die am Desktop angezeigt werden. Downloads/ für Files die im Web-Browser heruntergeladen wurden, etc.
In einer Text-Console wird man/frau üblicherweise mit einem ‘’Prompt” begrüßt. Der könnte z.b. So aussehen:
karli@meinlaptop:~$
Mit der Eingabetaste bekommt man einen neuen Prompt. Mit Pfeilnachoben oder Ctrl-P kann man in den Befehlen zurückblättern.
Ctrl-K löscht alles bis zu Ende der Zeile.
Wichtige Befehle um sich im Verzeichnisbaum zu bewegen:
Wer wie aus der Windowswelt gewohnt arbeiten will oder muss:
Alternativ kann man natürlich auch Texte mit LATEXverarbeiten und anstatt Berechnungen in einem Spreadsheet zu machen kann man echte Mathematik Software verwenden. Z.B. Octave.
Sehr viele Funktionen im Linux werden über normale, einfache Text Files abgewickelt. Diese enthalten keine Formatierung sonder nur reinen Text.
Konfigurationsdateien sind fast immer reine Text-Files. Skripte und Programmiersprachen verwenden reine Text-Files. LATEXist reiner Text. etc.
Sich gut in einem Text Editor zurecht zu finden ist eine der wichtigsten Skills die man/frau braucht um gut mit Linux zurecht zu kommen.
Idealerweise auch einen Text-Editor der alleine auf der Kommandozeile, also auch ohne grafische Oberfläche funktioniert.
Hier eine Übersicht über einige der gebräuchlichen Text Editoren:
Wie gesagt: Es reicht einen der Editoren gut zu beherrschen. Wer noch keinen der Editoren gelernt hat kann sich mit nano oder gedit durch schummeln.
Gimp ist ein sehr leistungsfähiges Bildbearbeitungsprogramm. Es dient zur Bearbeitung von Pixel-Grafiken und Fotos.
Neben Gimp gibt es noch sehr viele anderen Bildbearbeitungstools. z.B: kann man mit dem befehl import bla.png einen Screenshot machen und in die Datei bla.png speichern. import ist ein Tool aus dem ImageMagick Serie. Damit lassen sich auf der Kommandozeile über 200 Bildformate konvertieren.
feh und xli sind schnelle Bildbetrachter.
Auch zur Bearbeitung von Vektor Grafik gibt es viele Tools im Linux. Eines der Besten ist inkscape.
Das Inkscape eigene Format ist svg, das auch im Web inzwischen sehr gut unterstützt ist. Es lassen sich aber auch anderen Formate lesen und speichern. Auch das Konvertieren von und in Pixel-Formate ist möglich.
Hier ein kleiner Überblick über einige der wichtigsten Funktionen von inkscape:
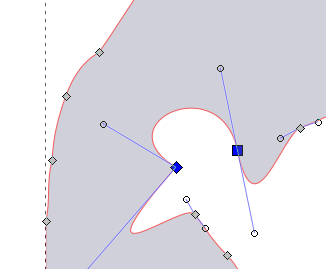
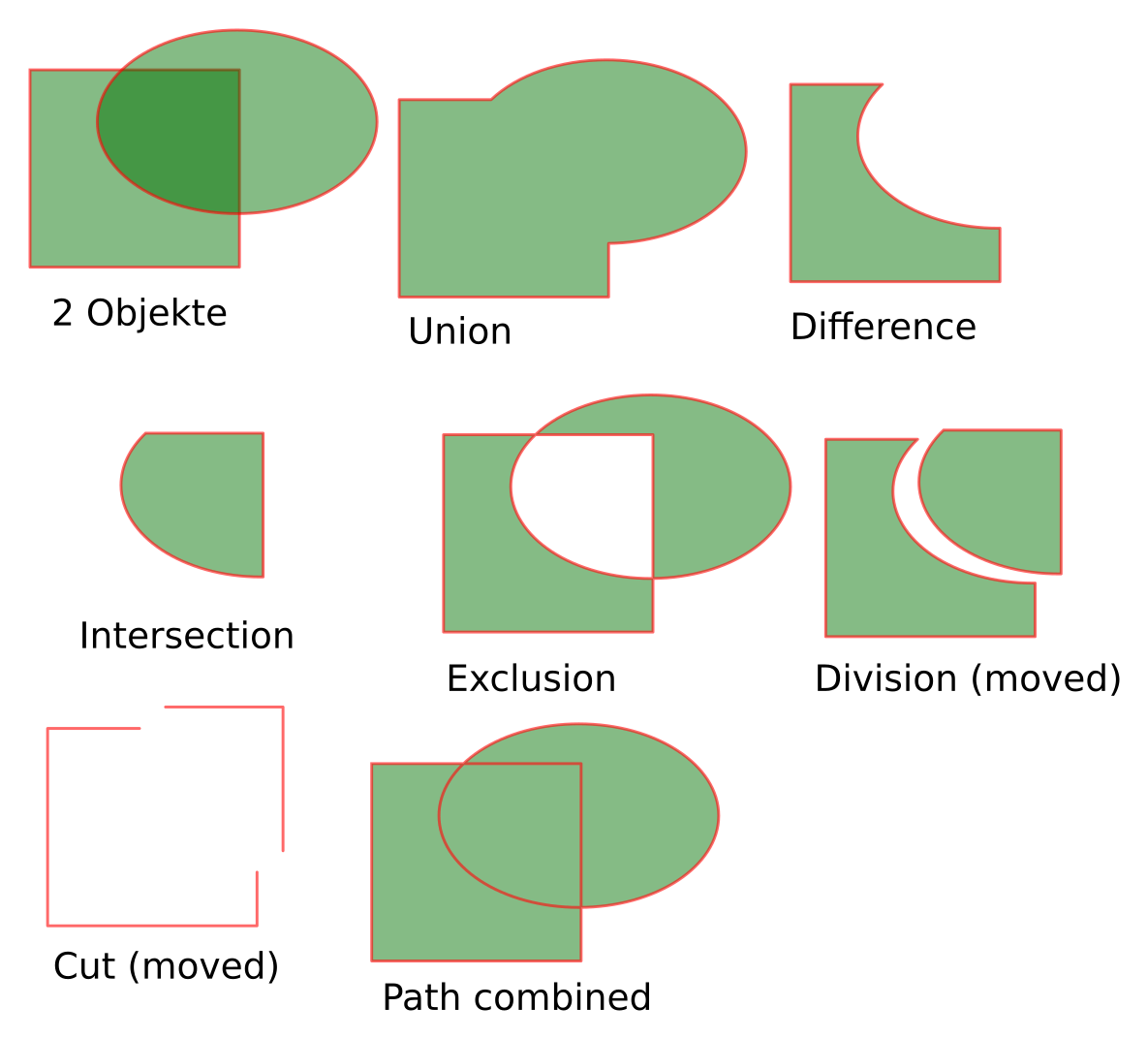
Desktop Publishing. Wie Adobe-Indesign, nur Frei. Wenn mehrere AktivistInnen gemeinsam eine kleine Zeitung (Poldi) oder einen Folder herausgeben wollen.
Blender ist ein extrem Leistungsfähiges 3D Programm. Es wurde für 3D-Animationen entwickelt und wird auch in professionellen Studios eingesetzt um Grafik-Effekte für Filme zu produzieren. Kann auch zum Filmschnitt verwendet werden. Aufgrund der vielen Funktionen gibt es aber einen hohen Lernaufwand. Ich setzte es auch ein um Modelle für 3-Druck zu erzeugen.
openscad ist ebenfalls zum Erzeugen von 3D-Strukturen, allerings mehr als Programm. Damit lassen sich parametrische 3D Objekte erzeugen und ist damit in der 3D-Drucker Community sehr beliebt.9
pdftk file1.pdf file2.pdf anhaenge*.pdf ouput ergebnis.pdf
pdftk original.pdf cat 17 155-158 2 320-end ouput auswahl.pdf
Wer eine professionelle LATEX- Umgebung benötigt ist mit Linux gut bedient. Da ist eine komplette latex-Installation mit allen Tools enthalten.
gcc, perl, python, …- Die meisten Programmiersprachen sind gut in Linux integriert.
karli@meinlaptop:~$
In einer Text-Console wird man/frau üblicherweise mit einem ‘’Prompt” begrüßt. Der könnte z.b. So aussehen:
Mit der Eingabetaste bekommt man einen neuen Prompt. Der Prompt lässt sich konfigurieren. Üblicherweise ist er so eingestellt dass wir sehen unter welchem User wir arbeiten, auf welchem System wir arbeiten (könnte auch eine sein, dass am anderen Ende der Welt steht) und das aktuelle Verzeichnis. ein $ sagt uns dass wir “normaler User” sind. Ein # ist i.a. für den root User.
Es gibt verschiedene Shell Programme die uns die Kommando-Eingabe ermöglichen. Default im Linux ist die bash. Alternativen sind tcsh (default bei Mac OS/X). Beliebt ist auch die zsh.
Mit den Befehlen pwd, cd, df, ls ls -l, ls -ltr (siehe voriges Kapital) können wir uns im Verzeichnisbaum bewegen und uns Dateien und Verzeichnisse ansehen.
who und w zeigen dir wer gerade aller am selben Computer eingeloggt ist. last zeigt dir wann du zuletzt eingeloggt warst.
Das großer-Zeichen: > leitet die Ausgabe eines Befehls, die ansonsten am Bildschirm landen würde (auch STDOUT genannt) in ein File um.
z.B.:
Würde die Ausgabe vom date Befehl in die Datei namens “heute.txt” schreiben. Achtung: Falls heute.txt schon existiert wird es kommentarlos überschrieben!
Den Inhalt der neu erstellten Datei können wir uns mit einem Editor oder mit dem cat Befehl ansehen: z.B.: cat heute.txt
cat gibt ein oder mehrere Dateien am Bildschirm aus. Natürlich lässt sich auch die Ausgabe von cat wieder mit > umleiten. Das Minuszeichen - wird sehr oft an Stellen benutzt an denen ein Filename verwendet werden kann um statt dessen die Eingabe (also die Zeichen die wir gerade eintippen, auch STDIN genann) zu lesen.
cat - > test.txt liest die Eingaben die wir tippen und schreibt sie in eine Datei namens text.txt. (Beenden der Eingabe mit Ctrl-D).
Analog dazu macht das Kleiner-Zeichen < eine Umleitung einer Eingabe. Ein Programm das normalerweise eine Eingabe lesen würde bekommt nun die Daten aus einer Datei. z.B:
Die Zeile mit dem seq 1 1000000 > mille.txt erzeugt eine Datei namens mille.txt mit den Zahlen 1 bis 1000000 als Inhalt. (Eine Zahl pro Zeile). Diese Datei leiten wir in das wc Tool um zu zählen wie viele Zeilen, Wörter und Zeichen dort drinnen sind.
Verwendet man statt einem > zwei >> so bedeutet das bei der Ausgabeumleitung, dass man eine eventuell vorhandene Datei nicht überschreiben will sondern den Inhalt am Ende anfügen will.
macht unsere mille.txt Datei noch um eine Zeile länger.
Fehlermeldungen werden von den meisten Tools nicht über die STDOUT Ausgabe ausgegeben sondern über einen einen Kanal “gesendet”. Der wird STDERR genannt und hat im Unix die Nummer 2. Will man dies Ausgabe auch umleiten dann Verwendet man 2 >. Soll die STDERR Ausgabe wie eine normale Ausgabe behandelt werden so können wir das mit dem Kürzel 2 > &1 machen.
z.B.:
* und ? haben in der shell eine spezielle Bedeutung. Sie sind “Wildcards” in Datei- und Verzeichnisnamen. Ein Stern * wird durch ein oder mehrere Beliebige Zeichen ersetzt. Ein Fragezeichen ? wird durch genau ein beliebiges Zeichen ersetzt:
Neben Doktor google, gibt es auch direkt im Linux viel eingebaute Hilfe.
Viele Befehle haben direkt Hilfe eingebaut. Mit den Optionen -h –help oder -help (leider nicht einheitlich) wird eine kurze Hilfe angezeigt. Diese Hilfe ist meist nur kurz und listet meist nur die Optionen auf.
Der help Befehl zeigt Hilfe zur aktuellen shell (BASH) an. help echo würde z.B. zum (intern in der shell eingebauten) echo Befehl anzeigen. Das funktioniert aber nur bei Befehlen die direkt, intern in der shell eingebaut sind. Für die meisten Befehle brauchen wir daher eine andere Hilfe:
man ist der Befehl zum Aufruf der manual Seiten. Die meisten Befehle haben solche man-pages.
man echo würde z.b. die man page zum echo Befehl ausgeben (der neben der eingebauten echo Funktion ebenfalls existiert).
man -k suchbegriff sucht in den Man-Pages nach “suchbegriff”.
man verwendet zur Anzeige der Seiten einen so genannten “Pager”. Da viele man-pages sehr lang sind kann man/frau damit in den Pages blättern.
Hier die wichtigsten Keyboard-Shortcuts für den Standard Pager. Der standard-Pager im Linux ist “less” und ist eine Weiterentwicklung von “more”.
Auf einer grafischen Oberfläche kann auch das Gnome-Help tool “yelp” verwendet werden: z.b.: yelp man:ls
Viele GNU Tools haben neben einer man-Page auch eine “info” Page. info ist etwas mühsam zu bedienen, aber kann dafür Links zu anderen info Seiten enthalten. Eine frühe Form von “hypertext”.10
Um zu sehen was auf deinem Linux gerade so läuft:
Das ps Kommando zeigt dir die aktuell laufenden Prozesse im System. Die Optionen “uax” und “elf” werden oft verwendet um mehr Info zu sehen als ps alleine anzeigt. Das pstree Tool zeigt eine Baumstruktur der Prozesse an (wer welchen gestartet hat).
Oft ist interessant zu sehen wer gerade die meiste CPU verbraucht. Dafür ist top nützlich. top ist ein interaktives Tool und listet die Prozesse nach ihrer CPU Auslastung. (Alternativ wird nach Speicherbedarf sortiert: nach dem Starten von top M (groß) drücken). Ein kleines q (quit) oder ein Ctrl-c beendet das Tool.
Alle Prozesse haben eine Nummer. Diese kann benutzt werden um die Prozesse zu steuern. z.B. um ihnen zu sagen sie sollen sich beenden:
kill 1234 würde dem Prozess mit der Nummer 1234 sagen, er soll sich bitte beenden. Notfalls muss das Betriebssystem mit dem Holzhammer nachhelfen: kill -9 1234 hilft dann.
Die bisher gelernten Befehle reichen für einfache Aufgaben. Wer etwas mehr in der Shell machen will benötigt aber noch einige Extras. Hier die wichtigsten davon:
Mit
kann eine verschlüsselte Konsole Verbindung zu einem anderen Linux Rechner aufgebaut werden. Dort können wir dann so arbeiten wie am lokalen Rechner. Mehr dazu im eigenen SSH Kapitel.
Find haben wir schon kurz erwähnt. Ohne Argumente listet es alle Datei und Verzeichnisnamen ab dem aktuellen Verzeichnis auf. Ein Argument wird als Verzeichnis gelesen, ab dem gesucht werden soll. z.B.:
Die Liste ist dabei meist recht lang. Um spezifischer suchen zu können gibt es sehr sehr viele Argumente im find. Hier einige der wichtigsten um die Suche einzuschränken:
Neben find gibt es auch noch das locate Tool. locate sucht überall - aber nicht live sondern nur in einer nächtlich erstellten Datenbank aller files. Dafür aber extrem schnell. Diese Datenbank wird z.B.: nächtlich erstellt und aufgefrischt.
Grep erlaubt das Suchen in Files nach so genannten “regular expressions”. Die werden wir nicht im Detail behandeln sondern nur die wichtigsten Fälle auflisten. Zum Üben benötigen wir zuerst einmal eine Datei mit viel Inhalt: z.B. find /etc > uebung.txt uebung.txt enthält jetzt eine Liste aller Files unterhalb von /etc. Die können wir jetzt durchsuchen:
Damit durchsuchen wir die Dateie uebung.txt und listen alle Zeilen die die Zeichenfolgen “ost” enthalten. Wir können natürlich auch jede andere Zeichenfolge versuchen. Hier die Wichtigsten Optionen für grep, die die Suche und die Ausgabe der Suche beeinflussen:
Die Optionen lassen sich natürlich auch kombinieren. z.B.:
Zeigt alle Files die die Zeichenfolge “ost” enthalten, ignoriert dabei Groß/Kleinschreibung, zeigt 3 Zeilen vor und nach jedem Treffer und gibt bei der Ausgabe die Zeilennummer mit an.
Hier noch einige Beispiele für “Regular Expressions”:
 bla
bla
Wir haben bereits gelernt wie wir die Ausgabe eines Programms in ein File umleiten (>) und wie wir die Eingabe zu einem Programm aus einem File lesen (<). Oft wollen wir uns den Zwischenschritt ersparen und einfach die Ausgabe eines Programms an ein weiteres Programm leiten. Dazu dient der Pipestrich (|). z.B.:
Hier verwenden wir das vorher gelernte grep Tool um die lange Ausgabe von find etwas zu filtern. Natürlich können zusätzliche Pipes benutzt werden um die Ausgabe wieder Weiter zu leiten. z.B.:
Würde aus der vorigen Ausgabe noch alle Zeilen entfernen (-v) die mindestens mit einer Ziffer enden.
Die meisten der Tools hier können auch direkt mit einem oder mehreren Files als Argument benutzt werden. Sehr praktisch sind sie aber auch innerhalb einer Pipe:
Hier ein Beispiel: Angenommen wir haben eine Liste an Namen die sich für eine Veranstaltung angemeldet haben und wir haben eine Zweite Liste von Namen die sich abgemeldet haben. Wir wollen nun eine alphabetisch geordnete Liste aller Namen die nicht abgemeldet sind.
Wie funktioniert das? Das cat gibt die anmeld.txt und abmeld.txt aus. Die abmeld.txt aber doppelt. D.h.: Jeder Name der in der abmeld.txt ist kommt mindestens 2 mal in der Ausgabe vor. (Falls er auch in der anmeld.txt vor kommt dann sogar 3 mal). sort sortiert die liste und uniq -u gibt nur noch die Zeilen aus die nur einmal vor kommen. Damit sind alle Enthalten die Angemeldet waren oder nicht in der Abmeldung aufscheinen. (Zur Sicherheit sollte zuvor überprüft werden ob in der anmeld.txt keine Doppelten vorkommen: cat anmeld.txt | sort | uniq -d )
Ein realistischers Beispiel: Wir haben in einem Verzeichnisbaum 2 Millionen Files und davon eine Kopie in der einige Files fehlen oder hinzu gekommen sind und wir wollen sehen welche das sind.
Neben de Argumenten und Optionen die einem Programm beim Starten übergeben werden gibt es noch eine Zusätzliche Möglichkeit den Programmen etwas Mitzugeben. Die so genannten “Environment Variablen”.
Die Variablen werden in der shell verwaltet. Variablen die zum “export” bestimmt sind, werden dabei auch an alle gestarteten Programme weiter gegeben. Alle nicht exportierten sind nur intern für die shell selbst sichtbar. Viele der Variablen werden auch benutzt um bash-Funktionen zu Speichern.
Wichtige Befehle zur Verwaltung dieser Variablen in der Bash sind:
Manche Variablen sind in der shell schon eingebaut und zeigen bestimmte shell-interne Zustände an. Andere werden per Konvention von Verschiedenen Programmen verwendet. Hier eine Liste der wichtigsten Variablen:
Die Variablen die wir interaktiv setzten sind nur in der aktuellen shell (und falls sie exportiert wurden, auch in den davon aufgerufenen Programmen) gültig. Wollen wir bestimmte Einstellungen permanent machen, so müssen wir die Variablen immer beim einloggen automatisch setzen. Es gibt folgende Möglichkeiten das zu tun:
Sehr beliebt in den profil-scripts sind alias Definitionen. Damit lassen sich Abkürzungen für Befehle definieren. Mit dem Befehl alias ohne Argumente können wir uns die aktuellen alias Definitionen ansehen.
Wie wir mit dem Pipe (|) Strich die Ausgabe von einem Befehl in den nächsten umleiten haben wir bereits gelernt. Was
aber wenn wir die Ausgabe eines Befehls in die Kommandozeile für einen anderen Befehl einsetzen wollen? Das geht in
der Bash mit $( befehlszeile ). Eine Variante die auch in andern Shells funktioniert sind die Backticks. Die einfachen
Anführungszeichen nach hinten: 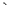 befehlszeile
befehlszeile .
.
Einige Beispiele:
Der erste Befehl gibt das Jahr und den Wochentag aus. (Es werden dabei spezielle Optionen des date Befehls benutzt.
Der zweite Befehl sucht alle Dateien (keine Verzeichnisse), die mit auf .jpg enden und kopiert sie in ein Verzeichnis namens archiv. Dabei gibt es einen möglichen Stolperstein: Da hier die Namen der Dateien mit Leerzeichen getrennt sind würde der Befehl fehlschlagen falls auch Dateien mit Leerzeichen im Namen vorhanden sind. Einer der Gründe um Leerzeichen in Dateinamen zu vermeiden. Ein weiterer: Die Länge der Befehlszeile ist beschränkt, aber meist kein Problem (Üblich auf einem modernen Linux 2 Millionen Zeichen).
Es gibt jedoch bessere Methoden um Befehle auf sehr viele Files anzuwenden:
Viele Befehle erlauben ohnehin mehre Files als Argument. Falls das nicht geht, oder falls die Liste der Files auf die ein Kommando angewendet werden soll erst durch ein Tool erstellt wird, gibt es mehrere Möglichkeiten.
Obiges würde den Befehl pdftotext für alle pdf Files aufrufen die unterhalb von Meinefiles/ liegen. Das {} wird durch den aktuellen Filenamen ersetzt.
Das xargs Tool liest Zeilen von STDIN ein und ruft für jede Zeile den Befehl auf der als erstes Argument angegeben wurde. Dabei kann angegeben werden wie viele Argumente maximal übergeben werden. Per default nimmt aber auch xargs Leerzeichen als Trennzeichen. Um das zu Vermeiden kann das Trennzeichen mit der Option -d explizit angegeben werden. Das Zeilenende kann mit \n angegeben werden.
der Output würde dann so aussehen:
find kann mit der option -print0 die Ausgabe mit Ascii-0 zeichen getrennt ausgeben. Diese können in Filenamen nicht vorkommen. xargs kann mit der Option -0 dieses Format lesen. Eine Leerzeichensichere Version der PDF in Text Konvertierung könnte also so aussehn:
Obwohl sich sehr viel in “Einzeilern” erledigen lässt ist es oft übersichtlicher und einfacher für komplexere Aufgaben ein so genanntes “shell script” zu schreiben. Ein script kann in verschiedenen Programmiersprachen geschrieben werden aber natürlich auch direkt mit der bash. Hier ein Beispiel für ein sehr einfaches script:
Was tut das script? Das Kanalgitter # beginnt in der shell einen Kommentar. D.h. was nach dem # kommt wird ignoriert. Die erste Zeile ist somit aus Sicht der shell auch ein Kommentar: #!/bin/bash
Die Kombination #! sagt allerdings dem Linux dass dieses script mit diesem Programm (eben der bash shell) ausgeführt werden soll.
Die nächste Zeile ist dann ein echter Kommentar und in den letzten Beiden Zeilen wird echo benutzt um eine Ausgabe am Bildschrim zu machen.
Wie können wir das script jetzt starten? Zuerst müssen wir es in ein File schreiben. z.b. meinscript.sh und danach müssen wir dem Linux sagen, dass dies ein ausführbares Script oder Programm ist. Dazu der Befehl:
Um das script dann wirklich auszuführen müssen wir den Namen des scripts eintippen. Da üblicherweise das aktuelle Verzeichnis nicht im $PATH Pfad ist müssen wir das explizit angeben. Also z.B.:
Hier noch ein Beispiel für ein etwas komplexeres script, das Files in thumbnails mit der breite 120 Pixel umwandelt.
Um das script laufen zu lassen müssen wir es wieder ausführbar machen und danach mit den passenden Argumente aufrufen:
Im Unix haben alle User einen Usernamen und eine numerische ID. Zusätzlich ist jede/r User Mitglied ein oder mehrere Gruppen. Um zu sehen welchen Gruppen wir angehören können wir den Befehl id verwenden:
Die Ausgabe könnte etwa so aussehen:
Wir sind also Benutzer “karli” mit ID 1000 und der primären Gruppe des selben Namens und der selben ID (1000). Weiters sind wir Mitglieder der Gruppen cdrom,audio,bluetooth und staff. Damit dürfen wir auf die entsprechende Hardware zugreifen und können auf Files zugreifen die der Gruppe “staff” zugeordnet sind.
Eine spezielle Rolle hat der user root (ID 0). Der/die darf alles. Dazu mehr später mehr.
Jedes File gehört immer eine/r BenutzerIn und einer Gruppe.
Die normalen Zugrifssrechte im Unix sind immer Dreigeteilt: Es gibt Rechte die auf den User selbst beschränkt sind dem/der die Datei gehört. Es gibt Rechte für die Gruppe der die Datei gehört und dann noch: Rechte für alle Anderen (“Other” manchmal auch “World”).
Die elementaren Rechte sind r: Lesen, w: Schreiben und x: Ausführen (execute). Der ls -l Befehl zeigt uns an wem eine Datei gehört und wie die Zugriffsrechte aussehen. Die Ausgabe ist dabei in drei Dreierblocks rwx jeweils für User Group und Other. Davor gibt es noch einen Buchstaben der Zeigt welcher Art das File ist. - zeigt normales File: z.B:
Die bla.txt darf nur von karli geschrieben werden (w) aber von allen anderen (Group und Other) geschrieben werden.
Die bli.txt darf neben karli auch von allen Mitgliedern der Gruppe “cdrom” gelesen werden.
Die blo.sh sowohl von karl als auch allen Mitgliedern der “staff” Gruppe gelesen, geschrieben und ausgeführt werden, aber von sonst niemanden.
Der letzte Eintrag ist ein Verzeichnis (zu erkennen am d am Anfang) namens Dok. Das Verzeichnis gehört anna die dort auch lesen und schreiben darf. Schreiben in einem Verzeichnis bedeutet hier: Files anlegen. Alle Mitgliede der staff Gruppe dürfen dort auch lesen (d.h. Files auflisten). Das x hat für Verzeichnisse eine spezielle Bedeutung. Ein fehlendes x verbietet jeglichen Zugriff auf alles was unterhalb dieses Verzeichnisses liegt, insbesondere auch auf Files auf die man/frau sonst Zugriff hätte. Niemand außer anna und die Mitglieder der staff Gruppe können also sehen was unterhalb von Dok liegt und können dort auch keine Files lesen, selbst wenn diese ansonsten von “Other” lesbar wären.
Andern BenutzerInnen ein File mit chown zu geben darf nur der/die root-UserIn. Die Gruppe darf man/frau auch nur auf Gruppen ändern denen man/frau selbst angehört. Obiger Befehl würde die Datei bli.txt der Gruppe staff zuordnen.
Obiger Befehl würde für Group und Others die Schreibrechte entfernen (falls vorhanden) und der zweite Befehl würde User, Group und Others Leserechte geben. Der Letzte Befehl gibt Allen alle Rechte auf das “kommunismus” Verzeichnis.
Wichtig für scripts (siehe oben) ist die execute Berechtigung für scripts:
Generell darf man/fau nur Rechte auf Files verändern die einem selbst gehören.
Werden im Unix relativ spärlich benutzt. Damit lassen sich auf Dateisystemen die dies unterstützen auch komplexere Rechte realisieren (z.B.: mehrere User die Rechte auf ein File haben obwohl sie nicht Mitglied einer gemeinsamen Gruppe sind). Mit getfacl können diese Rechte angezeigt werden und mit setfacl gesetzt werden.
Das + am Ende der Rechteanzeige deutet darauf hin das für dieses File noch spezielle ACLs gesetzt sind.
Der User mit dem Namen “root” und der BenutzerID 0 darf im Unix so ziemlich alles. Das entspricht in etwa dem “Administrator” im Windows.
Um root zu werden gibt es folgende Möglichkeiten:
Sofern wir das Passwort des root Users kennen, können wir einfach als root einloggen. Manche Systeme verbieten das Einloggen von root unter der grafischen Oberfläche, manche auch das root einloggen per ssh.
Auf der Text-Konsole (Ctrl-Alt-Funktionstasten) sollte aber ein root Login möglich sein.
su erlaubt es in der aktuellen shell den User zu Wechseln. Das Minus bedeutet dabei, dass nach Möglichkeit alles so eingestellt wird wie nach einem normalen Login. Mit su - kann man/frau daher root werden, solange das Passwort bekannt ist. su - andererbenutzer würde auf einen anderen Benutzer wechseln. Hier muss ebenfalls das Passwort dieses bekannt sein - ausser man/frau ist schon root, dann kann auf jeden Account gewechselt werden.
sudo ist ein Tool, das erlaubt bestimmte Befehle als ein/e anderer BenutzerIn auszuführen. Je nachdem wie sudo konfiguriert ist, darf man/frau dabei alle Befehle ausführen oder nur bestimmte und es wird entweder das eigene Passwort abgefragt oder nicht.
Live-CDs und Ubuntu sind i.a. so konfiguriert, dass der/die normale BenutzerIn sudo ohne Passwort verwenden darf. Man/Frau muss sich also kein zusätzliches root Passwort merken und kann dennoch root werden.
Benötigt man/frau nur einen einzelnen Befehle als root so können die direkt mit sudo ausgeführt werden. Wollen wir mehrere Befehle eingeben so ist es am einfachsten sich mittels sudo su - gleich eine volle root-shell zu besorgen.
Als root UserIn darf man/frau natürlich auch sudo selbst umkonfigurieren. Das geht mit dem tool visudo und ruft den default-Editor auf. Dort kann eingestellt werden, wer sudo aufrufen darf und wer damit welche Befehle aufrufen darf und auch ob ein Passwort für die Verwendung von sudo notwendig ist.
Siehe: Kapitel 9, Seite 14 (Passwort Sicherheit)
Passwort ändern sollte am besten über die grafische Oberfläche gemacht werden, da manche Distributionen mit dem Login-Passwort auch den Schlüsselsafe schützen. Ansonsten kann das Passwort mit dem passwd Tool geändert werden. Dazu muss das alte Passwort bekannt sein. Nur der/die root UserIn darf (alle) Passwörter ändern ohne die alten zu kennen (auch sein/e eigene/s).
tar ist ein Tool zum archivieren von Daten auf Band oder zum “zusammenzippen” von vielen Dateien in einer. In der DOS/Windows Welt ist das .zip-file bekannt. zip und unzip können auch im Linux verwendet werden, üblicher ist aber die Verwendung von tar und die damit generierten Archive mit den Endungen .tar .tgz .tar.gz .tar.bz2. Per Konvention nennen wir unkomprimierte Archiv-Files .tar, welche die mit dem gzip Tool komprimiert wurden .tar.gz oder kurz .tgz und welche die mit dem bzip2 Tool komprimiert wurden .tar.bz2.
Wenn z.b. alle Files unterhalb des Verzeichnisses Diplomarbeit/ in ein dipl.tgz File packten wollen so geht das mit:
Um zu sehen ob das geklappt hat (auflisten der enthaltenen Files in einem vorhandenen .tgz).
Wollen wir das dann z.b. in einem Unterverzeichnis namens “auspacken” auspacken:
Die wichtigsten Optionen von tar (können auch, wie bei anderen Programmen gewohnt, mit - geschrieben werden):
Das gzip Tool kann auch direkt verwendet werden um eine große Datei zu komprimieren. z.B.
Danach existiert ein File namens langes-file.txt.gz. Das kann mit gzip -d wieder ausgepackt werden.
Damit das tar-File ein wirkliches Backup ist, muss es natürlich entsprechend sicher Abgelegt werden. z.B.: über ein scp auf einem remote Server.
Um eine Kopie eines Verzeichnisbaumes, der an anderer Stelle aufgehoben wird aktuell zu Halten ist rsync ein gutes Tool.
Als grafisches E-Mail Tool verwenden die meisten Linux User den thunderbird. Im GNOME gibt es auch noch den Evolution - ist sehr Outlookähnlich.
Auf der Textoberfläche ist mutt ein extrem guter Email Client.
Auf der grafischen Oberfläche ist pidgin der beliebteste Chat-Client. Auf der Textconsole gibt es irc, irssi und andere.
dd ist ein Tool das Direkt von Disks lesen und schreiben kann. Damit müssen wir natürlich vorsichtig Umgehen. Sehr schnell kann eine ganze Festplatte gelöscht werden, sofern man/frau als root User arbeitet.
Um z.b. den Inhalt eines USB-Sticks der auf /dev/sdc eingebunden ist, 1:1 in einem File abzulegen würde folgender Befehl dienen:
Um ein leeres (mit Nullen gefülltes) File mit der Größe von 20MByte zu erstellen:
Die wichtigsten Optionen von dd sind:
Um z.b. einen bootbaren USB Stick zu machen, kann man/frau sich entsprechende Images von Live-CD Distributionen herunter laden. Diese können dann mit dd direkt auf dem Stick geschrieben werden. Der Stick sollte dabei nicht gemountet werden.
Um im Windows ein Disk Image auf einen USB Stick zu Schreiben ist normalerweise ein externes Tool notwendig. z.B: Microsofts Windows USB/DVD Download Tool oder rufus.
Drucken im Linux wird heute üblicherweise mit dem CUPS erledigt. CUPS ist ein System (Frei, von Apple entwickelt und auch in OS/X eingesetz) zur Verwaltung von Druckern und von Druckjobs.
Das CUPS System kann mit diversen Tools konfiguriert werden. Am einfachsten ist meist der Direkte Zugriff auf das CUPS Web System: Im Browser auf http://localhost:631 gehen. Um Drucker hinzufügen zu können muss man entweder als root oder als Bentuzer mit entsprechenden Rechten angemeldet sein. (d.h. es wird im Webinterface User und Passwort abgegragt).
Sinnvoll ist es die erweiterte Version des footmatic Packets zu installieren. Das bietet eine erweiterte Auswahl an Druckern und Druck-Filtern.
Hier auch noch einige CLI Tools für CUPS (wie gesagt: es ist auch alles im Webinterface auf http://localhost:631 sichtbar.
Der Drucker mit dem Namen PDF Druckt in PDF Files die im Homeverzeichnis des Benutzers unterhalb von PDF abgelegt werden. Ist also praktisch um PDFs zu erstellen (Falls ein Programm das nicht direkt kann) und um Testausdrucke zu sparen.
Ursprünglich wurde in Unix vor allem mit Postscript Druckern gedruckt. Es gibt nach wie vor eine sehr große Zahl an Tools die mit Postscript umgehen können. Hier eine kleine Übersicht über einige nützliche PS Werkzeuge:
Die Daten in einem Windows oder Linux System sind normalerweise nur durch die Passwortabfrage beim Einloggen geschützt. Wird aber z.b. die Festplatte ausgebaut oder der PC mit einem USB-Stick oder einer Live-CD gebootet, so sind die Daten direkt lesbar.
Ein gutes Passwort ist natürlich wichtig, es schützt aber eben nicht davor wenn Jemand direkten, physischen Zugang zum Computer hat.
Ähnlich ist es mit Daten die Über das Netzwerk übertragen werden. Werden diese im Klartext übertragen so können alle die das Netzwerk abhören können (Internet Provider, der Hersteller deines WLAN Routers, die 13 Jährigen Script-Kiddies im offenen WLAN, Geheimdienste) die Daten lesen.
Wo wird Verschlüsselung Eingesetzt:
Wenn ein/e HackerIn auf deinem Computer eingebrochen ist, dann kann er/sie natürlich alles Lesen was du eintippst und auf alle deine Files zugreifen. Die Festplattenverschlüsselung nützt dir dort gar nichts - weil ja beim laufenden System die Festplatte immer entschlüsselt wird. Deine verschlüsselten Files sind auch nur ein bedingter Schutz: Solange du sie nicht entschlüsselst sind sie sicher. Gibst du aber deine Passphrase für die Entschlüsselung ein ist der Schutz dahin.
Das selbe gilt natürlich für den Schutz der Daten auf der anderen Seite: Wenn wir mit jemanden oder mit einem Server kommunizieren müssen wir auch damit rechnen dass auf der anderen Seite ein/e HackerIn sitzt.
Auch VPN und TOR schützt nicht 100%ig: Mit Bugs in deinem Browser kann unter Umständen ein Webserver herausfinden von welcher echten IP Adresse du kommst.
Auch die Festplattenverschlüsselung schützt nicht 100%ig vor Menschen mit physischen Zugang. Es könnte z.B. jemand in dein Hotelzimmer einbrechen und auf deinem Laptop einen neuen Bootloader installieren, der mit einem Backdoor ausgestattet ist und die Eingegebene Passphrase ausspioniert. (Evil Maid Attack).
Auch wenn der Schutz niemals 100%ig ist: Wir sollten doch nach Möglichkeit auf die Sicherheit achten. Wir sollten auch Daten verschlüsseln die nicht besonders oder vielleicht gar nicht geheim sind: Denn wenn nur die Menschen Verschlüsselung benutzen die wirklich heikle Daten haben dann machen sich diese Menschen erst recht Verdächtigt. Insofern macht es Sinn auch die Glückwünsche an die Oma zu Verschlüsseln.
Folgende Probleme werden üblicherweise mit cryptografischen Techniken behandelt:
Zur Sicherstellung der Integrität werden so genannte Hash-Funktionen benutzt. Die Erzeugen eine Prüfsumme, also einen Digitalen Fingerabdruck von Daten. Idealerweise so, dass es nicht möglich ist den gleichen Fingerabdruck von anderen Daten zu bekommen.
Tools um einen Fingerabdruck von Dateien zu bekommen sind: md5sum sha1sum sha256sum sha512sum MD5 ist nicht mehr wirklich sicher aber manchmal ausreichend. SHA512 und SHA256 sind noch sicher.
Obwohl die Daten sich nur sehr wenig unterscheiden, sind die Hashes total verschieden. Wollen Anna und Berta sicher gehen, dass ihre Daten die selben sind könnten sie sich, z.b. Via Telephon die Hash-Summen durchsagen.
In klassischen (symmetrischen) Verschlüsselungstechniken haben die Beiden Parteien die eine Nachricht austauschen wollen einen gemeinsamen, geheimen Schlüssel für die Kommunikation.
Eine, idealerweise etwas längere, Zeichenfolge oder ein Satz wird als so genannte “Passphrase” verwendet. Daraus wird mit einer mathematischen Funktion ein Schlüssel errechnet, der zur Verschlüsselung der Daten verwendet wird.
gpg (GNU Privacy Guard) ist ein Tool mit dem sowohl symmetrische als auch Public-Key Verschlüsselung möglich ist. Um ein File symmetrisch zu verschlüsseln: ]
Wollen sehr viele Parteien miteinander kommunizieren müsste jeder mit jedem einen Satz geheimer Schlüssel vereinbaren. Das wäre ziemlich hoher Aufwand, vor allem weil die Schlüssel ja zuerst über einen sicheren Kanal (z.b. ein persönliches Treffen) ausgetauscht werden müssten.
Leichter wird das mit so genannten Public-Key Verschlüsselungsystmen. Dort gibt es 2 Schlüsseln: einen zum Verschlüsseln und einen völlig anderen zum Entschlüsseln. Der Schlüssel zum Entschlüsseln kann dabei nicht leicht aus dem zum Verschlüsseln abgleitet werden. Das Schlüssel-Paar (geheimer und öffentlicher Teil) wird i.a. gemeinsam Erzeugt. Damit kann ich z.B.:
Mir einen Schlüssel-Paar machen und den Öffentlichen Teil in der Zeitung abdrucken lassen. Alle LeserInnen können mir dann geheime Nachrichten schicken. Ich kann sicher sein dass nur ich diese lesen kann. Einziges Problem: Die LeserInnen können nicht ganz sicher sein: Die Redaktion könnte eine Eigenes Schlüsselpaar haben und deren Öffentlichen Teil abgedruckt haben. Um sicher zu gehen könnte ich in einem TV interview bestätigen, dass der in der Zeitung abgedruckte Schlüssel auch wirklich meiner ist und ich könnte dort z.B. den sha256 Fingerprint des Schlüssels vorlesen.
Die meisten Public-Key Systeme können auch für digitale Unterschriften verwendet werden. Ich kann also künftig Nachrichten veröffentlichen und die Zeitungsleser können sicher sein, dass die digitale Unterschrift (z.B. ein Verschlüsselter sha256-Fingerprint der Nachricht) wirklich von mir ist.
Das Abdrucken des Schlüssels in der Zeitung ist allerdings nur für Promis praktikablen. Normalerweise werden Schlüssel auf sogennanten Key-Servern veröffentlicht. Dort können sie öffentlich heruntergeladen werden. Dann muss natürlich immer noch überprüft werden ob der Schlüssel tatsächlich der Person gehört, deren Email Adresse im Key angeführt ist.
Dazu gibt es 3 Möglichkeiten:
Eines der ersten Public-Key Verschlüsselungswerkzeuge war PGP (“Pretty Good Privacy”), das das RSA-System der Allgemeinheit zugänglich machte. Allerdings ist und war PGP nie frei. Als freie alternative gibt es GPG (“GNU Privacy Guard”):
GPG bietet neben symmetrischer Verschlüsselung (Siehe: Kapitel 20.5, Seite 68) alle Funktionen die für Public-Key Systeme benötigt werden:
GPG ist ein reines CLI Tool. Es gibt aber grafische Oberflächen dafür. Im Linux z.B. seahorse zur Verwaltung und im Gnome-Filebrowser eingebaute (via Plugin: seahorse-nautilus ) Verschlüsselung per Mausklick.
GPG startet im Hintergrund ein Programm namens gpg-agent der die Eingegeben Passphrase für den Key merken kann. Um GPG zu erlauben die Passphrase zu lesen ist es eventuell notwendig zuerst
zu setzen.
Hier die wichtigsten GPG Funktionen:
Alternativ kann mit der --clear-sign Option gesagt werden, dass der originale Text in der Nachricht im Klartext aufscheint. Oder wir verwenden die Option --detach-sign - damit wird eine Signatur erzeugt, die getrennt von der Originaldatei ist. Im Falle einer Email würde man/frau dann sowohl die unverschlüsselte Originaldatei versenden, als auch die Unterschrift dazu.
Um die Tatsache, dass überhaupt verschlüsselte Nachrichten ausgetauscht werden zu verbergen, können diese in anderen Nachrichten versteckt werden. Das nennt sich “Steganographie”. Mit dem steghide Packet können Texte in Bildern oder Audiodateien versteckt werden.
Es ist ziemlich gefährlich Passwörter mehrfach zu benutzen: Gelingt es Hackern ein Passwort auf einem System zu stehlen ist damit auch die Sicherheit auf den anderen Systemen gefährdet. Wir sollten daher auf jedem System ein anderes Passwort verwenden. Hunderte von Websites wollen, dass wir uns dort mit Username und Passwort anmelden, aber wer kann sich all die Passwörter merken?
Um dieses Problem zu lösen gibt es Passwort Manager.
Dort werden Passwörter in einem Verschlüsselten File gespeichert und bei bedarf können wir dann nachsehen.
Den Passwortmanager selbst sollten wir natürlich nur auf einem sicheren System betreiben. Welche Möglichkeiten gibt es dafür?
Es gibt als viele Möglichkeiten. Was tun? Ich würde vorschlagen die wichtigsten Passwörter jedenfalls Browser-Unabhängig zu speichern. (z.B. via “pass”). Bei weniger wichtigen (Junk) Websites die ein Passwort benötigen ist es durchaus OK diese auch im Browser zu speichern.
Ganz wichtige Passwörter, das Master Passwort und die GPG-Passphrase sollte man/frau sich aber einfach nur merken. Für entsprechende Online-Accounts sollte auch (Two-Factor Authentication) aktiviert werden (Einloggen mit One-Time-Codes oder Handy-SMS).
Gerade auf Laptops sollte die Festplatte mit LUKS (dm-crypt) verschlüsselt werden. Debian bietet dies beim Setup als Option an. Alternativ kann mit dem cryptsetup Tool eine Verschlüsselte Partition erzeugt werden.
Beim Starten muss dann immer eine Passphrase zur Entschlüsselung eingegeben werden. Sollen mehre User den selben Laptop benutzen können auch mehrere Passphrases verwendet werden. Um z.B. auf einer vorhandenen Partition einen Key hinzuzufügen:
Daneben sollte auch ein Passwort für den GRUB-Bootloader gesetzt werden:
https://www.theurbanpenguin.com/securing-the-boot-process-with-grub-passwords/ und wir sollten im
BIOS (dem Menü sofort nach dem Einschalten, in das wir meist durch Drücken des DEL oder F10 Taste kommen.)
einstellen dass wir nicht von 
USB, CD oder Netzwerk booten wollen und die Einstellungen mit einem Passwort schützen. Paranoide Menschen schützen die Schrauben ihres Laptops noch mit Glitter-Nagellack. (Siehe: Kapitel 20.1, Seite 66 - Evil-Maid Attack).
Wer z.B. einen kleinen Linux Server irgendwo betreibt oder einen Account auf so einem Server irgendwo anders hat oder wer von der Arbeit aus schnell mal einen Zugriff auf die Daten am Computer daheim benötigt, lernt schnell die Vorteiel und Eleganz von ssh.
SSH steht für “secure shell”. Secure, weil es mit Verschlüsselung arbeitet und “shell” weil es in erster Linie Zugriff auf eine Textoberfläche - shell - gibt.
Angenommen Anna hat einen Account namens “anna” auf dem Server: meinserver.at und kennt ihr Passwort dort.
Dann kann sie, ausser es ist eine Firewall dazwischen, mit dem Befehl
und der Eingabe ihres Passwortes dort einloggen und dann auf der Textoberfläche als Benutzerin anna arbeiten.
Angenommen sie ist auf dem Computer von dem aus sie die ssh Verbindung aufbaut auch als User anna eingeloggt, dann kann das anna@ ausgelassen werden.
Wenn wir jetzt zum testen keinen Account auf einem anderen Server haben können wir natürlich via ssh andereruser@localhost auf den eigenen Rechner einloggen und so tun als ob (Eventuell müssen wir dazu erst den ssh-server Teil installieren).
Die Verbindung zum entfernten (remote) Server ist verschlüsselt. Damit ist Anna davor geschützt dass ihr Internet Provider oder die Leute die das selbe WLAN benutzen ihre Verbindung abhören können. Ihr Internet Provider (ISP) sieht allerdings nach wie vor, dass sie eine Verbindung zu diesem Server aufbaut und wie viele Daten dort hin und hinaus gehen. Wir sind ebenfalls davor geschützt, dass unser ISP die Daten zu einem anderen Server umleitet und wir dort versehentlich unser Passwort eingeben, vorausgesetzt wir beachten den Fingerprint. Siehe unten.
Angenommen ihr eigener Rechner wurde gehackt. Dann schützt das ssh natürlich gar nicht, denn die Hacker können all ihre Tastatureingaben und alles mitlesen. Auch wenn sie die Verbindung von einem Internet-Cafe aus aufbaut: Alle Trojans die dort installiert sind können die Verbindung abhören und auch ihr Passwort mitlesen.
Angenommen der Server auf den wir einloggen ist gehackt. Sobald wir mit einem Passwort einloggen kann er Hacker auf der anderen Seite unser Passwort lesen. Das ist nur dann ein zusätzliches Problem falls wir das selbe Passwort auch für andere Server benutze hätten. Aber inzwischen wissen wir ja dass wir das nicht dürfen.
Mit dem Befehl scp können wir über ssh auch Files kopieren. z.B.:
Der erste Befehl würde alle mit IMG2019 beginnenden .jpg Files aus dem Pictures Ordner auf den anderen Server ins Verzeichnis /var/www/Bilder/ kopieren (sofern dieses Verzeichnis existiert und anna dort schreiben darf).
Der Zweite Befehl kopiert die Datei bla.txt aus dem Homeverzeichnis von anna von meinserver.at ins aktuelle Verzeichnis (der Punkt am Ende).
Gnome und KDE Filebrowser haben übrigens auch das ssh Protokoll eingebaut es wir können via Ctrl-L und sftp://anna@meinserver.at auch grafisch auf die Daten zugreifen.
SSH-Clients gibt es auch für andere Betriebssysteme. Hier eine Auswahl:
Neben dem einloggen mit Passwort kann ssh auch Public-Key Logins.
Dazu generieren wir uns ein Paar aus öffentlichen (.pub) und privaten Schlüssel, danach sagen wir dem Server er soll unseren öffentlichen Schlüssel vertrauen und dann können wir mit unserem privaten Schlüssel einlogen. Klingt recht kompliziert ist aber im ssh sehr einfach:
Das wars. Danach können wir ohne Passwort einloggen. Das ssh-keygen Erzeugt unser Schlüsselpaar (in der ssh Terminologie: eine Identität). Die Schlüssel werden, wie alle anderen persönlichen ssh Einstellungen unterhalb des .ssh/ abgelegt. Per default unter dem Namen .ssh/id_rsa.pub und .ssh/id_rsa. Wir könnten aber, falls wir mehrere Schlüssel wollen, mit der Option -f auch einen anderen Namen für den Key angeben - in diesem Falle bekommt der Public-Teil ein .pub am Ende.
Wichtig: Das ssh-keygen fragt nach einer Passphrase. Diese wird benutzt um den Key zu verschlüsseln. Hier unbedingt eine gute und lange Passphrase verwenden: gelingt es jemand deinen .ssh/id_rsa private Key zu stehlen und ist dieser nicht mit einer Passphrase geschützt, dann können die HackerInnen auch auf den meinserver.at und alle anderen Server die den Key erlauben.
ssh-copy-id macht ein Login auf den remote Server (hier meinserver.at) und installiert dort den Public-Key (per default: .ssh/id_rsa.pub, so dass dieser ohne Passwort einloggen darf. Dazu wird am remote Server im File .ssh/authorized_keys eine neue Zeile eingefügt in der der .pub key eingetragen wird. (Das könnten wir ohne dem ssh-copy-id script auch händisch machen.)
Moment mal: Wir wollten ohne Passwort einloggen und jetzt müssen wir stattdessen eine noch längere Passphrase verwenden. Wo ist denn da der Vorteil?
Ein Vorteil ist, dass es halbwegs sicher ist den selbe Public-Key auf mehreren Servern zu erlauben. Wir können also mit einem Key und einer Passphrase einloggen. Dass die Passwörter alle unterschiedlich sind braucht uns nicht mehr zu kümmern. Und auch das Eintippen der Passphrase lässt sich reduzieren. Die meisten Distributionen starten beim Login ein Programm namens ssh-agent. Der ssh-agent kann die Passphrase “cachen”. D.h. wir tippen sie nur einmal ein und können dann für die Dauer unserer Session überall ohne Passwort einloggen.
Mit dem ssh-add Tool können wir dem Agent auch sagen dass wir eine Identität (Public/Private Paar) hinzufügen wollen oder mit ssh-add -D alle wieder aus dem Cache entfernen.
ssh-add -l zeigt uns alle momentan aktiven Identitäten an.
Im Textfile .ssh/config können wir persönliche Einstellungen für SSH ablegen. Besonders nützlich ist es oft sich alias Namen für die verschiedenen Server anzulegen auf denen wir einloggen. z.B.:
Diese Einträge im .ssh/config legen Aliasnamen für ssh an. Anna kann ab nun auf den server web-server3.meinserver.at einfach mit web ansprechen und den Server beispielserver123.example.com einfach mit bs. Also z.B.:
Die Einstellung SendEnv sagt dem SSH dass es die lokalen Variablen EDITOR LANG und alle Variablen die mit LC beginnen beim einloggen mitübertragen soll. Damit wird auf der anderen Seite der selben default EDITOR und die selbe Sprache verwendet (falls diese dort installiert ist und falls der Server diese Variablen erlaubt).
Die anderen Einstellungen (Forward…) behandeln wir etwas weiter unten.
Wollen wir auf dem remote Server nur einen einzigen Befehl ausführen, dann können wir den direkt als Argument dem ssh übergeben. z.B.:
Damit loggen wir auf den web-Server ein den wir oben definiert haben und führen nur einen einzigen Befehl aus: du -hs /var/www/Bilder (Die Anführungszeichen könnten wir in diesem Falle auch weglassen). Der Befehl würde uns z.B.: den belegten Platz im /var/www/Bilder Verzeichnis anzeigen.
Das erscheint auf den ersten Blick nicht so spektakulär. Viel an Tippaufwand haben wir nicht gespart. Allerdings: Wir können den Pipe Strich | und die Dateiumleitungen < und > Verwenden um Daten zwischen dem lokalen und dem remote System zu übertragen. z.B.:
Mit diesem Befehl verwenden geben wir auf der remote Seite das mein.pdf aus (cat). Die Ausgabe wird über die ssh Verbindug zu uns umgeleitet. Aber da wir ein pdf File am Bildschirm ohnehin nicht lesen können leiten wir es in das pdftk Tool um. Im obigen Beispiel sagen wir dem pdftk Tool es soll seine Eingabe von STDIN (-) beziehen (also die Daten die es per Pipe hineingefüttert bekommt) und dann die Seiten 17 bis 20 Auswählen und auf bla.pdf (lokal) abspeichern. Natürlich geht das auch in die andere Richtung:
Obiges Beispiel würde mittels des dd Programmes vom Gerät /dev/sdh lesen. Das könnte z.B. ein USB Stick sein oder eine alte Festplatte. Da das File recht groß ist wollen wir es nicht lokal abspeichern sondern gleich zum Server übertragen. Wenn nichts anderes Angegeben so gibt dd die Ausgabe gleich auf STDOUT und das wir in diesem Falle mit dem Pipe Strich zur Eingabe von ssh. ssh leitet das über den Verschlüsselten Tunnel auf den remote Server und dort starten wir das Programm ”cat -”. Das liest die Eingabe (-) und gib es auf STDOUT wieder aus. Die Ausgabe haben wir dann in ein File namens usbimage.img umgeleitet. Wir hätten es aber z.b. Auch dort wieder in ein dd umleiten können um dort z.B.: eine Kopie des USB Sticks zu erzeugen.
Das direkte Angeben von Befehlen ist recht nützlich, insbesondere wenn wir Abläufe automatisieren wollen. D.h. Wir wollen z.b. Immer um 3 Uhr nachts ein Backup machen und mit ssh die Daten auf einen anderen Server kopieren. Oder wir haben einen kleinen Raspberry-Pi der das Garagentor aufmachen kann und den wollen wir vom Handy aus aktivieren. Oder wir wollen einer externen Firma erlauben das Bild einer Webcam auf unserem Server upzudaten.
Wenn Sachen automatisch, durch ein Script gesteuert passieren sollen, dann ist dort niemand der eine Passphrase eintippen kann - wir würden also einen Schlüssel verwenden der nicht mit einer Passphrase (einer leeren Passphrase) gesichert ist. Aber das wäre erst recht wieder ein Risiko. Um diese Probleme zu lösen gibt es die Möglichkeit einzuschränken was ein bestimmter SSH Key darf:
Im File .ssh/authorized_keys stehen die Public-Keys die ohne Passwort einloggen dürfen. Einer pro Zeile. Vor dem Key, also am Zeilenanfang können wir verschiedenen Einschränkungen festlegen.
(Das kommt alles in eine Zeile und ist nur hier, der Lesbarkeit halber, umgebrochen). Die wichtigste Einschränkung ist das command= dahinter steht ein Befehl oder ein Script. Und dieses Script oder dieser Befehl ist das einzige das mit dem Key ausgeführt werden darf.
Das updatewebcam.sh Script könnte z.b. so Aussehen:
Und der Befehl mit dem von der externen Firma das Bild gesendet wird könnte so aussehen.
Mit dem curl Befehl lädt die Firma das Bild selbst übers Netzwerk. z.B.: von einer internen Webcam. Die Ausgabe des Bildes schickt curl auf STDOUT. mit ssh wird das dann zum Account von anna auf meinserver.at weiter geleiet. Der Befehl der hier angegeben wird (dummy) ist egal. Es wird ohnehin immer updatewebcam.sh ausgeführt. Mit der Option -i kann eine andere Identität - d.h. ein anders Private-Key File angegeben werden. Hier z.B: eines das extra für den Webcam update angelegt wurde. Bei anna ist dort der zugehörige Private Key im authorized_keys File eingetragen.
Falls das remote System das erlaubt können mit SSH neben der Shell-Verbindung gleichzeitig auch anderen Verbindungen aufgebaut werden, mit denen andere Daten/Protokolle übertragen werden. Dabei haben wir 4 Arten von Tunnel. Hier jeweils mit Beispiel:
Linux kann auf sehr viele Arten starten. Welche genutzt wird hängt auch davon ab auf welchem System gearbeitet wird. Am Raspberry-Pi funktioniert Booten ganz anders als auf einem PC. Hier die wichtigsten Stadien des Boot-Vorganges auf einem PC auf dem der übliche Bootloader (grub) verwendet wird:
Normalerweise muss man hier nicht eingreifen. Aber für Notfälle ein Überblick über die wichtigsten systemd Funktionen. Das meiste hier ist natürlich nur für den/die root-UserIn benutzerbar.
Beim Aufsetzen einen neuen Linux kann man/frau durchaus die vom Installationssystem vorgeschlagenen default Werte akzeptieren. Insbesondere wenn Linux das Einzige System auf der Festplatte ist.
Es lohnt sich aber doch ein wenig zu Verstehen wie die Aufteilung einer Festplatte erfolgen kann und wie man z.B. Filesysteme von externen USB-Festplatten einbinden kann, ….
Im Windows sind die verschiedenen Festplatten i.a. getrennte Laufwerksbuchstaben (C: D: …). Im Linux können sie an beliebiger Stelle im Verzeichnisbaum hängen. Um dennoch zu sehen was ein eigener “mount” ist, kann man/frau die Befehle mount oder df nutzen.
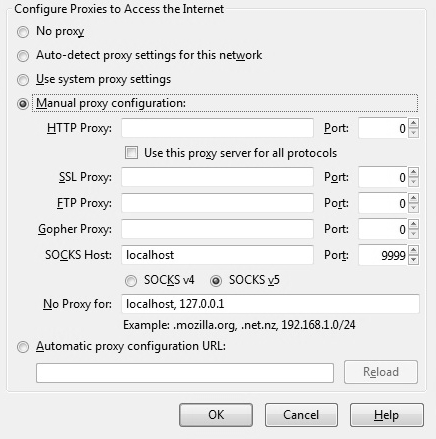
Hier ein Überblick über die Terminologie:
Im Bild rechts haben wir 2 Festplatten. Die sda mit 3 Partitionen sda1, sda2 und sda3 und die zweite mit einer Partition sdb1. In neueren Systemen mit großen Festplatten wird auch neuere GPT Partitionierungsystem eingesetzt.
Festplatten haben den Nachteil dass sie leider immer im ungünstigsten Moment sterben. Hat man/frau 2 oder mehr Festplatten eingebaut dann empfiehlt sich die Verwendung eines RAID (“redundant array of independent disks”). Dabei werden die Daten immer auf 2 oder mehr Platten gepiegelt. Das ersetzt zwar kein Backup (Daten können immer noch z.B. versehentlich gelöscht werden oder der Computer wird gestohlen, …) bringt aber dennoch einiges an Datensicherheit. Mit dem mdadm Befehl kann aus 2 etwa gleich großen Partitionen ein RAID1 gemacht werden, bei dem die Daten auf beide Festplatten (sinnvollerweise wählt man/frau Partitionen auf unterschiedlichen Platten).
Würde ein neues RAID Device namens md0 anlegen das aus den Teilen sdb7 und sdc7 besteht.
Wichtig ist es das RAID zu überwachen. Denn der Ausfall einer Festplatte wird sonst leicht übersehen und dann sind die Daten beim Ausfall der zweiten Festplatte doch weg. In /etc/mdadm/mdadm.conf sollten die Konfigurierten RAIDs eingetragen werden. Dort kann auch eine Email-addresse angegeben werden die beim Ausfall verständigt werden soll.
Zusätzlich schadet es nicht öfter mal cat /proc/mdstat aufzurufen um den Status des RAIDs zu überprüfen.
Die relativ fixe Partitionierung hat ihre Nachteile: Meist wird irgend eine der Partitionen voll und man/frau würde sie gerne Vergrößern aber das geht nicht weil dahinter eine andere Partition liegt.
In einem modernen Setup wird daher schon oft LVM (“Logical Volume Mangement”) verwendet. Damit lassen sich Daten sehr flexible über physiche Partitionen verteilen und flexibel erweitern.
Hier die wichtigsten Tools und die Terminologie von LVM
Neure LVM Versionen unterstützen auch schon direkt innerhalb LVM realisierte RAIDs und es gibt Kontrolle darüber auf welchen PVs bestimmte LVs zu liegen kommen. Snapshots (zu einem bestimmten Zeitpunkt eingefroren Zustände) von LV waren immer schon möglich. Für Traditionelle (“thick”) LVs aber sehr langsam. Mit den inzwischen schon stabilen “thin” LVs können auch sehr schnell Snapshots angelegt werden.
Kommt man/frau zu einem unbekannten Linux System und will sich einen Überblick über das dort laufende LVM machen so empfehlen sich die Befehle:
pvscan, vgscan und lvscan. Diese durchsuchen die Festplatten nach LVMs und geben diese aus. Startet man/frau von einer Live-CD und findet auf einem nicht laufenden System ein LVM so müssen die VGs und LVs erst aktiviert werden.
Um die, in den vorigen Kapiteln erlernten Sachen in der Praxis ausprobieren zu können, brauchen wir nicht gleich einen eigens Linux aufsetzen. Wir können das auch in einer simulierten Umgebung tun. Für Virtualisierung gibt es viele Möglichkeiten (Siehe: Kapitel 6.2, Seite 10). Wir machen das hier mit KVM.
KVM steht für “Kernel Virtual Maschine” und ist eine “hardware beschleunigte” Virtualisierung. D.h: es werden bestimmte Features der CPU benutzt um die Virtualisierung möglichst effizient zu machen. Das virtualisierte System sollte daher nicht all zu viel langsamer Laufen als ein originales.
KVM benutzt sehr viel vom QEMU-System. QEMU ist aber eine reine Software-Virtualisierung. QEMU kann auch andere Computer Systeme (mit anderen CPUs) simulieren. QEMU kann auch auf Mac und Windows Systemen laufen. Ein KVM ist im wesentlichen eine QEMU-Virutalisierung Plus Hardware Beschleunigung.
Wenn wir in einem Terminal auf der grafischen Oberfläche einfach nur kvm eintippen, starten wir die Emulation eines PCs. Es erscheint ein Fenster in dem ein Boot-Prozess abläuft. Da wir keine virtuelle Festplatte haben klappt das mit dem Boot natürlich nicht.
Klicken wir in das Fenster, dann nimmt sich der Emulator die Maus. Um dort wieder heraus zu kommen können wir Ctrl-Alt drücken. Ctrl-Alt-f toggelt zwischen Fenster und Fullscreen Modus.
Ein Ctrl-C im Textfenster in dem KVM gestartet wurde beendet dies wieder. Alternativ kann KVM auch ganz ohne simulierten Bildschirm gestartet werden.
Auf der Befehlszeile können sehr viele Parameter angegeben werden um verschiedene virtuelle Hardware zu simulieren.
Zuerst wollen wir uns eine virtuelle Festplatte erzeugen:
Das qemu-img Tool wird hier verwendet um eine neue, simulierte Festplatte im qcow2 Format zu erzeugen die 4G groß ist und im File demo.qcow2 abgelegt ist. Das qcow2 Format erlaubt es Festplatte zu simulieren die viel größer sind als sie eigentlich Platz benötigen und die erst mit dem Schreiben von echten Daten wachsen. (Direkt nach dem Erstellen benötigt unsere 4G große Festplatte nur 193k).
Alternativ könnten wir auch ein Disk Image verwenden in dem der Platz 1:1 dem Entspricht was wirklich auf der virtuellen Festplatte liegt (ein so genanntes raw Image). z.B.:
Wir wollen uns nun in diesem virtuellen PC ein Debian-Linux installieren und suchen uns nun die debian-9.6.0-amd64-netinst.iso Installations-CD.
Mit diesem Befehl wird jetzt unser kvm wieder gestartet. Wir simulieren eine deutsche Tastatur und 2G Hauptspeicher (hat unser Host Computer weniger als 3G sollten wir hier eventuell weniger verwenden. z.B.: 1G).
Wir simulieren ein CDrom Laufwerk in das unser ISO-Image als CD eingelegt ist und zum Schluss unsere virtuelle Festplatte: demo.qcow2.
Wollen wir 2 Festplatten dann wäre der Syntax z.B.:
Hier hätten wir eine qcow2 Festplatte und eine mit einem raw-Image.
Wir können nun den Debian Setup Prozess mit verschiedenen Optionen ausprobieren. Zum lernen wäre z.b. Folgendes Setup sinnvoll:
Weiters könnten wir
Geben wir am GRUB Boot Bildschirm:
Ein Linux ohne Netzwerkverbindung ist für die Meisten Zwecke nicht wirklich nützlich. Auch wenn das Setup des Netzwerkes in den meisten Fällen automatisch geht ist es praktisch notfalls Probleme selbst diagnostizieren und beheben zu können. Dazu benötigen wir zumindest Grundkenntnisse davon wie Netzwerke funktionieren. Das soll, zusammen mit dem zugehörigen Linux Befehlen hier vermittelt werden.
Auf Laptops und normalen Arbeitsplätzen wird i.a. der “NetworkManager” gestartet. Der kümmert sich um die Herstellung einer Verbindung. Findet er eine Kabel- (LAN) Verbindung so benutzt er diese. Ansonsten sucht er nach WLAN-Netzwerken und erlaubt mithilfe der grafischen Oberfläche deren Konfiguration. Sind die Netzwerke so eingestellt, dass eine IP-Adresse automatisch zugewiesen (DHCP-Protokoll) wird sollte das ausreichen.
Als Abstraktion von der realen Netzwerk-Hardware (z.B: einer Netzwerkkarte) kennt Linux das so genannte “interface”.
Mit dem Befehl ifconfig können die vorhandenen Interfaces samt ihrer Einstellung aufgelistet werden. ifconfig -a zeigt dabei auch Interfaces die momentan nicht in Verwendung sind, aber vorhanden wären.
Das ifconfig Tool ist allerdings nicht mehr ganz taufrisch und man/frau sollte heutzutage eher das ip Tool verwenden. Zur Anzeige der Interfaces kann entweder
verwendet werden. ip addr listet dabei alle Interfaces samt ihren IP-Adressen. ip link zeigt die Hardware (MAC) Adressen. Die Option -s zeigt jeweils auch Statistiken an.
Die IP-Adressen werden zum Datenaustausch ins globale Internet und zwischen lokalen Netzwerken benutzt (OSI-Layer 3). Die MAC-Adessen sind die lokalen Adressen innerhalb des Netzwerkes. Jede Netzwerkkarte hat eine global eindeutige MAC-Adresse. Zur Kommunikation im Internet muss jedenfalls eine IP-Adresse zugewiesen werden.
Zeigt die Zuordnung von IP-Adressen und MAC Adressen die im lokalen Netzwerk gefunden wurden (also die von anderen Computern im Netz).
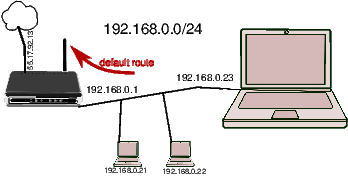
Ein typisches kleines Heimnetzwerk sieht z.B.: so aus:
Es gibt einen, meist WLAN-fähigen Router der die Verbindung zum Internet herstellt. Der Router arbeitet intern mit privaten Adressen die nicht im Internet geroutet werden und schreibt diese transparent auf die eine öffentliche Adresse um. Üblicherweise 192.169.0.0/24 Diese Schreibweise gibt zuerst eine Netzwerkadresse an und dann die Zahl der Bits im Netzwerk die zum Netz gehören, die restlichen Adressen dienen dann dazu um Computer im Netz zu unterscheiden. In diesem Beispiel also: 192.169.0.0 bis 192.169.0.255. Wobei die unterste und die oberste Adresse für spezielle Funktionen reserviert sind.
Netze für den privaten Gebrauch sind:
Oder Teile davon. Also z.B.: 192.169.207.0/24 oder 10.119.180.0/24.
Im gezeichneten Beispiel haben wir das klassische 192.168.0.0/24 Netz. Der WLAN Router hat hier die Adresse .1 (.1 ist für Router üblich aber nicht zwingend). Der WLAN Router vergibt die Adressen für die angeschlossenen Geräte. Hier scheinbar ab .20. Unser Laptop hat hier die .23.
Am Router kann man/frau normalerweise einstellen, dass anhand der MAC Adresse immer die selbe IP Adresse zugeordnet wird - oder es wird eine fixe Adresse am Computer selbst eingestellt - idealerweise nicht aus dem Pool der automatisch vergebenen - um Konflikte zu vermeiden.
Die Adressen der Computer im selben Netz werden auf ip neigh auftauchen, sobald sie miteinander sprechen.
Der Computer hat eine so genannte “Routing-Table” die festlegt, wo andere IP Adressen als die lokalen gesucht werden. Für die meisten Heim-Netzwerke haben wir hier nur eine so genannte “default route” die sagt: Alle IP Adressen sind hinter einem bestimmten Router. Im Heimnetzwerk der WLAN Router. Im gezeichneten Beispiel 192.169.0.1
Debian/Ubuntu etc. haben ihre Netzwerkeinstellunge in /etc/network/interfaces
Hie ein Beispiel wie das aussehen könnte:
Im obigen Beispiel wird da so genannte “loopback interface” konfiguriert, das bekommt die Adresse 127.0.0.1 und geht immer zum eigenen Rechner. Ist also für Selbstgespräche gedacht. Danach eine Fix-IP Addresse. Statt der /24 Schreibweise wird die Netzmaske ausgeschrieben. Darunter ist ein gateway angegeben. Der wird dann benutzt um die default route zu setzen.
Es gibt noch viele andere Optionen die nützlich sind. Auch die MAC Adresse kann hier, falls notwendig, verstellt werden. Sehr nützlich ist auch die up Option z.B.: up /root/myfw.sh . Der Befehl oder das Script nach up werden ausgeführt sobald das Interface in Betrieb geht. Dort können wir z.B: Firewall Regeln einfügen.
Auskommentiert ist die Einstellung die die Netzwerkkarte automatisch mit DHCP konfigurieren würde.
Ein wichtiges Element der Netzwerk-Config ist auch der “Name-Server”. D.h. Jener Server im Internet der die Umsetzung von Namen (z.B: www.orf.at ) auf IP Adressen (z.B: 194.232.104.150) erledigt. Ist dieses Service nicht verfügbar so würden zwar alle IP Adressen funktionieren aber die Internet-Nutzung ist dennoch nicht praktikabel.
cat /etc/resolv.conf Zeigt die aktuell eingestellten Nameserver (können auch mehr sein - es braucht aber mindestens einen). Diese Datei wird üblicherweise auch automatisch befüllt (z.B.: via DHCP).
Hier eine Liste an Befehlen zur Fehlersuche im Netz:
telnet war der Vorgänger von SSH. Es ermöglichte textorientierte Remote-Verbindungen aber ohne Verschlüsselung. Das wird Heute kaum noch verwendet, allerdings ist das Tool weiterhin nützlich um zu testen ob ein Netwerkservice verfügbar ist.
z.B.:
Mittels telnet www.orf.at 80 können wir uns auf das Port 80 (dort findet sich das unverschlüsselte http Protokoll) verbinden. Wir sehen ob der Server “abhebt” d.h. eine Verbindung überhaupt erlaubt.
Mit telnet localhost 22 können wir z.B. schnell herausfinden ob auf unserer lokalen Maschine ein SSH (Das Port dafür ist 22) läuft.
Ein Übersicht über alle lokalen, vom Netzwerk aus erreichbaren Services bekommen wir mit:
Die erste Zeile zeigt TCP-Services (t) und die Zweite UDP-Services (u).
netstat ist auch nützlich um die gerade aktuell aktiven Netzwerkverbindungen anzuzeigen.
Im normalen IP (IPv4) Netzwerk gibt es maximal 232 == 4Gig Adressen. Bei fast 8 Millionen Menschen hier wird das, trotz NAT nicht reichen. Die neue Version von IP hat dann 2128(ca.3.4 * 1038) Adressen. Linux unterstützt schon lange IPv6.
Die Adressen sehen in etwa so aus: fe80::2a6f:cffb:f3a:cef9 Es werden immer 4 Hex Stellen geschrieben, wobei führende 0en weggelassen werden.
Ein Linux mit mehr als einem Netzwerkinterface kann auch als Router arbeiten. Das muss aber zuerst eingestellt werden.
Linux kann auch als Firewall arbeiten: Einerseits um sich selbst zu schützen, falls das Linux als Router arbeitet kann es auch ein Netzwerk schützen. Auch als NAT kann Linux eingesetzt werden.
Es gibt normale 3 Firewall Tabellen: INPUT (Um Packte zu filtern die an uns gerichtet sind). OUTPUT zum Filtern der lokal versendeten Netzwerkpackte. Die Regeln in der FORWARD Tabelle werden nur benutzt wenn das Linux als Router arbeitet und Packte von einem Interface zu einem anderen weiterleitet.
Dann gibt es 2 Tabellen für NAT auf die wir hier nicht näher eingehen.
Hier im schnelldurchgang die Wichtigsten Befehle rund um iptables Firewalls.
-A fügt neue Regeln am Ende der Tabelle an. (d.h. vorher eingefügte Regeln haben Priorität). ACCEPT erlaubt diese Packte. DROP verwirft sie kommentarlos. -s gibt die Source Adresse an.